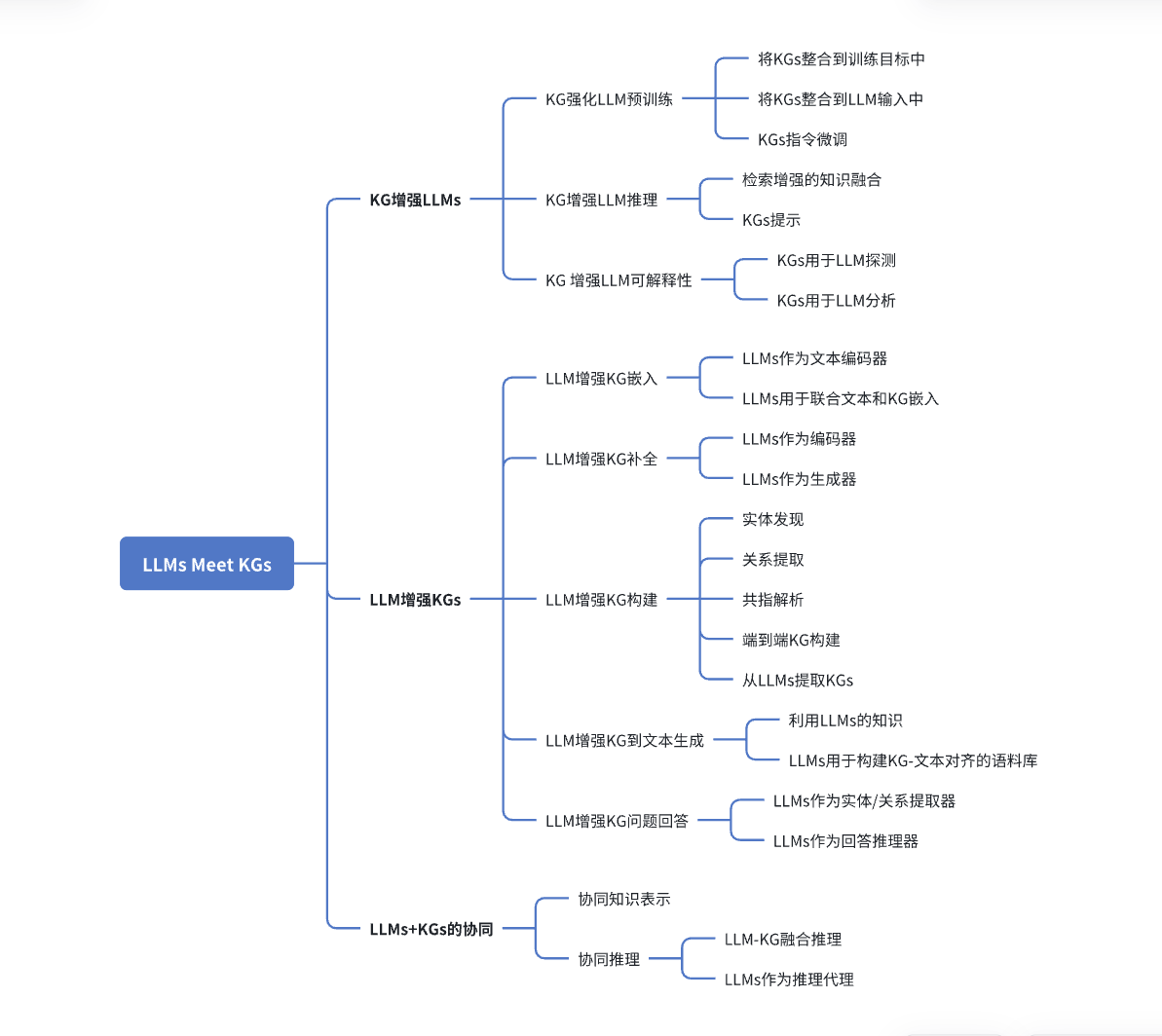
知识图谱
一、知识图谱
1.1 基本概念
知识图谱,在2012年由谷歌提出,是结构化的语义知识库,用于以符号形式描述物理世界中的概念及其相互关系。
基本组成形式(基本单位):<实体,关系,实体>构成的三元组。

图1:知识图谱
1.2 数据类型和存储方式
知识图谱的原始数据类型一般来说有三类:
- 结构化数据(Structed Data),如:关系数据库、链接数据
- 半结构化数据(Semi-Structured Data),如:txt、PDF、XML、JSON、百科
- 非结构化数据(Unstructured Data),如:图片、音频、视频
知识图谱的存储方式主要分为两种:
资源描述框架(RDF):RDF是一种用于描述网络上资源及其关系的标准格式。RDF使用三元组来表示实体及其关系,RDF存储的优点在于其标准化和互操作性,可以方便地与其他语义数据进行集成。然而,对于非常复杂或大规模的数据集,查询性能可能会成为一个瓶颈。
图数据库(Graph Databases):图数据库专门为处理图结构数据而设计,使用节点和边来表示实体及其关系,具有很高的查询性能和灵活性,常用的有 Neo4j,JanusGraph等,适用于大规模和关系复杂的数据场景,具有高效的查询性能和灵活性。
1.3 构建流程
逻辑架构
- 数据层:存储真实的数据。
- 模式层:在数据层之上,模式层定义了知识图谱的组织结构和类型体系,是知识图谱的元数据部分。
示例: 假设我们有一个关于电影的知识图谱,数据层可能包含以下信息:
- 《泰坦尼克号》是一部1997年上映的电影。
- 詹姆斯·卡梅隆是《泰坦尼克号》的导演。
- 莱昂纳多·迪卡普里奥在《泰坦尼克号》中扮演杰克。
这些信息以三元组的形式存储,在数据层与模式层:
- (《泰坦尼克号》——上映年份——1997)<——>(实体——属性——属性值)
- (《泰坦尼克号》——导演——詹姆斯·卡梅隆)<——>(实体——关系——实体)
- (莱昂纳多·迪卡普里奥——扮演角色——杰克)<——>(实体——关系——实体)
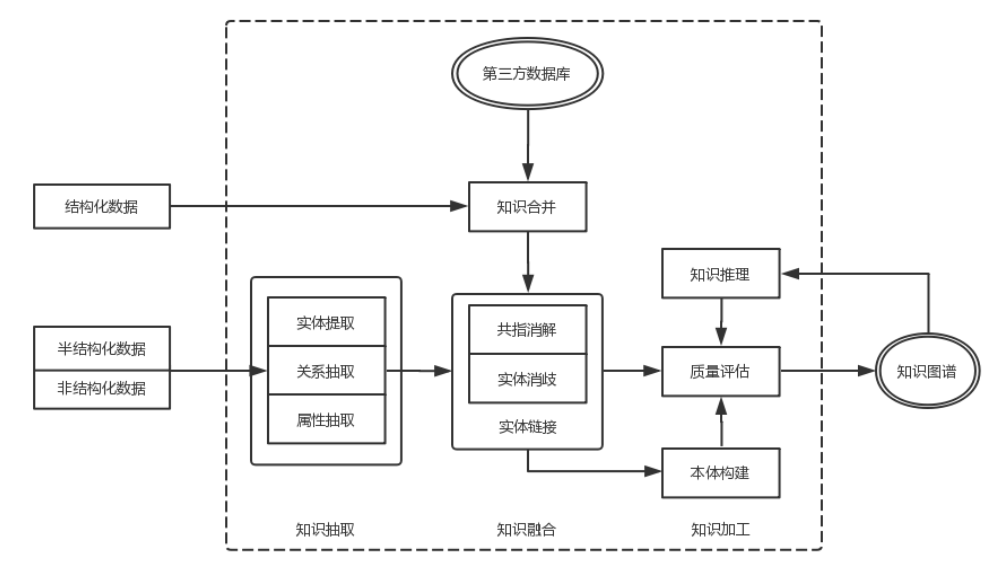
图2:知识图谱构建流程
知识抽取
从各种类型的数据源中提取出实体、属性以及实体间的相互关系,在此基础上形成本体话的知识表达。
- 实体抽取:也称为命名实体识别(named entity recognition,NER),是指从文本数据集中自动识别出命名实体。
- 关系抽取:为了得到语义信息,还需要从相关语料中提取出实体之间的关联关系,通过关系将实体联系起来,才能够形成网状的知识结构。
- 属性抽取:从不同信息源中采集特定实体的属性信息。
知识融合
在获得新知识之后,需要对其进行整合,以消除矛盾和歧义,比如某些实体可能有多种表达,某个特定称谓也许对应于多个不同的实体等。
实体链接:对于从文本中抽取得到的实体对象,将其链接到知识库中对应的正确实体对象的操作,针对半结构化数据和非结构化数据。
- 同名实体产生歧义问题——实体消歧。
- 假设存在两个版本的《泰坦尼克号》电影,一个是1997年詹姆斯·卡梅隆导演的版本,另一个是1958年的早期版本。在抽取过程中,如果文本中提到了《泰坦尼克号》,我们需要确定它指的是哪一个版本。
- 电影中可能有一些虚构的角色,它们与真实人物同名。例如,电影中可能有一个虚构的配角也叫“詹姆斯”。而在一些影评中可能存在对导演“詹姆斯·卡梅隆”的评价,需要通过实体消歧来确定这个“詹姆斯”是否是电影中的一个虚构角色。
- 多个指称对应同一实体对象的问题——共指消解。
- 例如在文本中提到“男主角杰克”和“他在电影中的表现”,共指消解将帮助我们确定这两个指称(“男主角杰克”和”他”)都是指向《泰坦尼克号》中的角色“Jack Dawson”。
- 在影评中可能同时出现“男主角”和角色名“杰克”,我们需要确定它们都指的是同一个人。
知识合并:处理结构化数据,比如外部知识库和关系数据库。
- 假设已有一个外部数据库提供了《泰坦尼克号》的详细信息,包括演员、工作人员、上映日期等。我们的知识库可能已经有了一些这部电影的信息。知识合并的过程将包括:
- 核对外部数据库中提供的数据与知识库中的信息是否一致。
- 解决任何数据冲突,例如,如果外部数据库中列出的上映日期与知识库中的日期不符,需要进一步验证哪个是正确的。
- 将外部数据库中的额外信息(如电影的技术规格、获奖情况等)添加到知识库中,以丰富《泰坦尼克号》的条目。
- 假设已有一个外部数据库提供了《泰坦尼克号》的详细信息,包括演员、工作人员、上映日期等。我们的知识库可能已经有了一些这部电影的信息。知识合并的过程将包括:
知识加工
通过知识抽取以及知识融合后,获得了一系列基本的事实表达,但这些不等于知识。要想最终获得结构化、网络化的知识体系,还需要经历知识加工的过程。
知识加工主要包括三个方面的内容:本体构建、知识推理和质量评估。
本体构建:本体提供了一个框架,定义了可以存储在知识图谱中的实体类型、属性和关系。
- 实体类型:定义电影、导演、演员、角色、电影公司等实体类型。
- 属性:为每种实体类型定义属性,例如电影可能有属性如上映日期、类型、票房、导演、主演等。
- 关系:定义实体之间的关系,如“导演执导了电影”、“演员扮演了角色”等。
这一整个知识图谱的框架就是一个本体。
知识推理:经过本体构建后,形成了一个知识图谱的雏形。但这时候,知识图谱的缺失值可能很严重,因此需要使用知识推理,利用已有的知识来发现新知识,填补知识图谱中的缺失信息,增强知识之间的联系。
质量评估:
- 质量评估的目的是量化知识的可信度,确保知识库的质量。通过评估,可以识别并舍弃那些置信度较低的知识,从而维护知识库的准确性和可靠性。
- 质量评估可能包括多个方面,如数据源的可靠性、数据的一致性(检查是否存在矛盾或冗余问题)等。
二、 LLM 背景下的知识图谱
2.1 知识图谱分类

图3:不同类别知识图谱示例
知识图谱按存储信息大致可以分为以下四类:
- 百科全书式知识图谱
百科知识图谱是最普遍的知识图谱,它代表了现实世界中的常识。百科全书知识图通常是通过整合来自不同和广泛来源的信息来构建的,包括人类专家、百科全书和数据库。
- 常识知识图谱
常识知识图谱表述了有关日常概念的知识,例如对象和事件及其关系。与百科全书式知识图相比,常识知识图往往对从文本中提取的隐性知识进行建模
- 特定领域知识图谱
特定领域的知识图通常被构建来表示特定领域的知识,例如医学、生物学和金融。与百科全书式的知识图谱相比,特定领域的知识图谱往往尺寸更小,但更准确、更可靠。
- 多模态知识图谱
与仅包含文本信息的传统知识图不同,多模态知识图以图像、声音和视频等多种模态表示事实。
2.2 LLM与KG统一框架
《Unifying Large Language Models and Knowledge Graphs: A Roadmap》一文中提出了 LLM 和 KG(知识图谱)统一的三个框架。
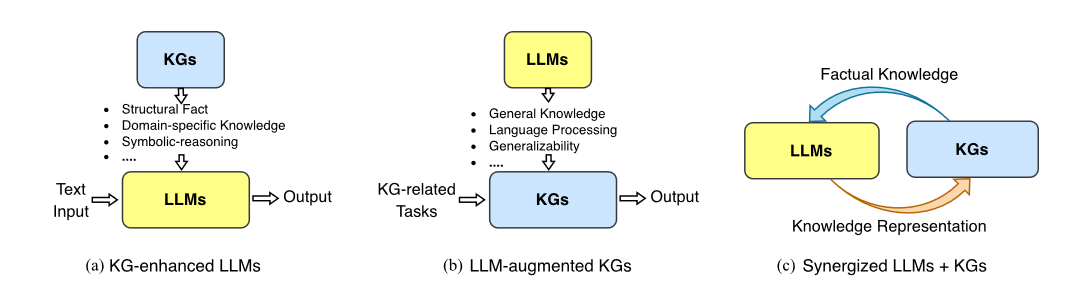
- KG增强LLMs:
- 目的:通过整合知识图谱中的结构化和领域特定知识来改进LLMs。这种整合主要发生在LLMs的预训练和推理阶段。
- 优点:通过提供事实和结构化知识,增强了LLMs的理解和推理能力。
- LLM增强KGs:
- 目的:利用LLMs的能力执行有利于KGs的任务,如KG嵌入、完成、构建、图到文本生成和问题回答。
- 优点:通过利用LLMs的自然语言处理能力,旨在简化和提高KG相关任务的准确性。
- LLMs + KGs的协同:
- 目的:LLMs和KGs在一个互利的设置中共同工作,以增强彼此的能力。这种协同旨在优化知识表示和推理过程。
- 优点:促进双向推理,数据和知识驱动性能在复杂任务中的提升,导致在需要文本理解和事实知识的应用中更好的结果。