LangGraph
LangGraph
基础概念
State
state 代表图中节点的状态,通常用于存储节点或图的计算结果。状态是图中每个节点在执行过程中的“记忆”,它保存了执行过程中产生的中间结果或最终结果。它可以是任何 Python 类型,但通常是TypedDict或 Pydantic BaseModel 。(类型化字典)
1 | # 定义状态类型 |
Nodes
节点通常是一个对 State 进行操作的python函数,是图的基本组成单元。每个节点代表一个具体的操作或任务,通常是某种数据处理、调用外部 API等。一般有两个参数,state 和 config,config 为可选参数。
节点示例:
1 | # 定义节点函数 |
特殊节点:
START节点,表示将用户输入发送到图形的节点。引用该节点的主要目的是确定应该首先调用哪些节点。END节点,代表终端节点。当您想要指示哪些边完成后没有任何操作时,将引用此节点。Conditional Entry Point节点,代表条件入口点。根据自定义逻辑从不同的节点开始。
1 | from langgraph.graph import START, END |
Reducers(化简器)
reducer 是一种函数,用于控制节点(node)更新状态(state)的方式。每个状态键都有自己的独立 reducer 函数,决定如何处理节点对该键的更新。如果没有明确指定 reducer 函数,则默认所有更新都会覆盖状态中的对应键值。
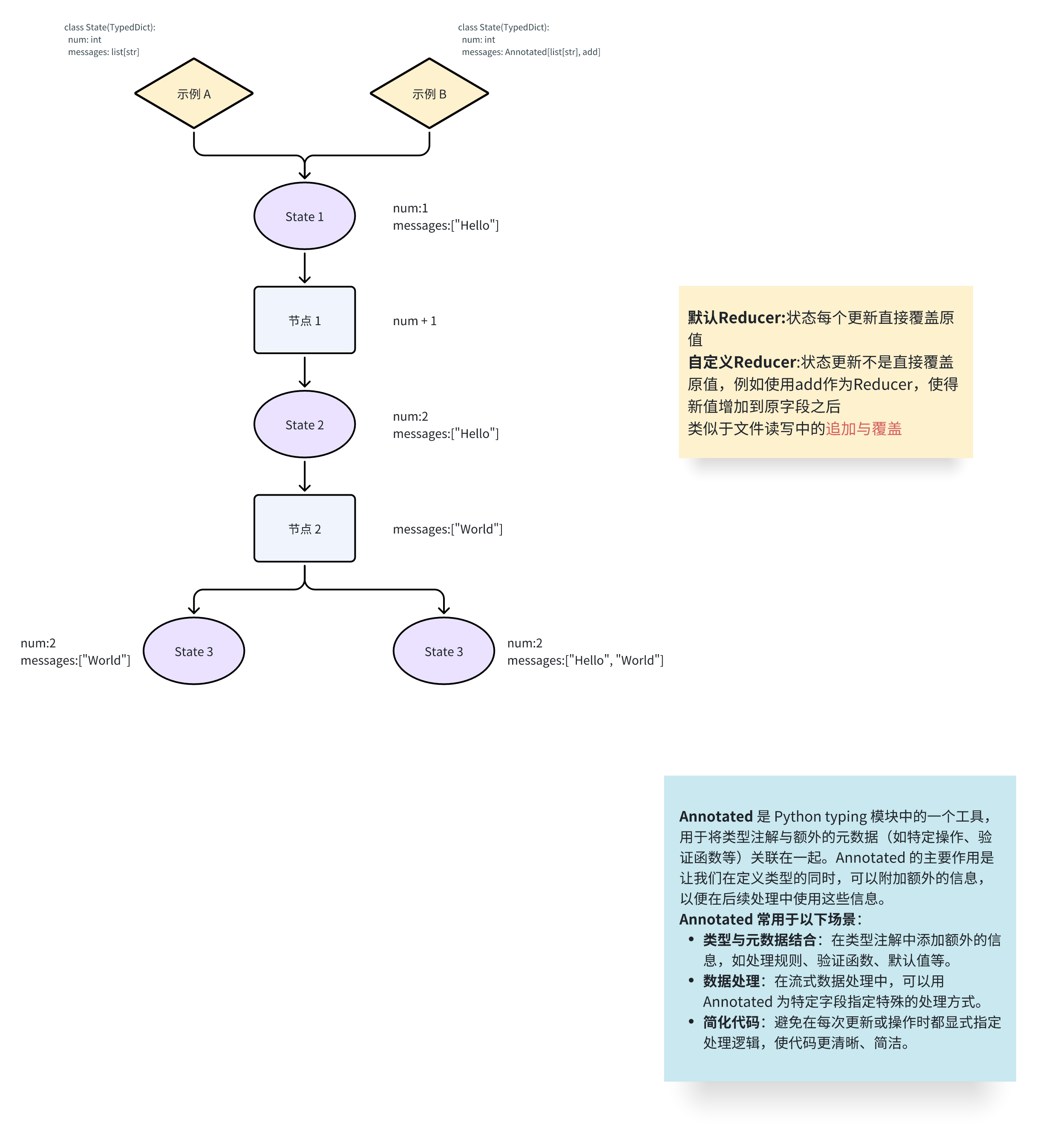
在与LLM交互中可以使用与构建的add_messages函数,对于全新的消息,它只会附加到现有列表,但它也会正确处理现有消息的更新。
1 | class State(TypedDict): |
State、Node 和 Reducer 之间的关系
- 数据流动:
Node从State中获取输入,进行计算或操作并生成输出。Reducer负责将这些输出合并回State,决定最终的状态更新方式。- 协作方式:
Node是图的计算核心,执行具体的操作。State存储Node的输入和输出,实现数据的共享与传递。Reducer确保Node输出的数据可以合并到State,避免直接覆盖造成的数据丢失。
Edges
Edges用于连接不同的节点(Nodes)并定义节点之间的依赖关系和数据流。边描述了一个节点的输出如何成为下一个节点的输入,从而建立起一个有序的任务流。
Edges 的类型:
- 普通边(Normal Edges)
直接连接两个节点,使用add_edge函数。
1 | graph.add_edge("node_a", "node_b") |
- 条件边(Conditional Edges)
允许根据特定条件将数据或状态路由到不同的节点。这种边的用途在于,当图执行时,可以根据条件动态地决定执行哪个节点,或者是否终止图的执行流程。
示例:
新建一个图,其中包含 node_a、node_b 和 node_c。在执行完 node_a 后,根据特定条件决定接下来执行 node_b 或 node_c。
使用 add_conditional_edges 方法来实现条件路由:
- node_a:表示条件判断节点,即在这个节点执行后,判断下一个要执行的节点。
- routing_function:一个函数,根据当前的状态(state)返回一个值。这个值用于决定下一个要执行的节点。
1 | graph.add_conditional_edges("node_a", routing_function, {True: "node_b", False: "node_c"}) |
Send
Send 是 LangGraph 中的一种特殊机制,用于在动态情况下向下游节点传递不同的状态。这种机制在节点和边的数量在图定义时未知的情况下非常有用。
- 动态生成多个任务:某个节点可能输出一个列表,你希望为列表中的每个元素生成一个单独的任务。
- 每个任务有独立状态:每个任务需要接收不同的状态,而不是共享同一个全局状态。
示例(生成笑话):
- 起始节点
node_a生成一个包含主题(subjects)的列表,例如["cats", "dogs", "robots"]。 - 你希望为每个主题生成一个笑话(joke)。这意味着需要为每个主题创建一个独立的节点
generate_joke。
具体实现:
- 定义一个节点函数
continue_to_jokes:
1 | def continue_to_jokes(state): |
输入:state,包含一个键 subjects,例如 {"subjects": ["cats", "dogs", "robots"]}。
输出:
- 每个主题(如
"cats","dogs","robots")都生成一个Send对象。 Send对象包含两部分:- 目标节点名称:
"generate_joke"。 - 传递的状态:如
{"subject": "cats"}。
- 目标节点名称:
- 添加条件边:
1 | graph.add_conditional_edges("node_a", continue_to_jokes) |
在 node_a 执行后,调用 continue_to_jokes 函数。根据state["subjects"] 的内容,动态生成多个边,分别将状态传递给不同的 generate_joke 节点。
CheckPoint
检查点(Checkpoint)是用于保存图执行过程中状态快照的机制。每当图执行到一个超级步骤(super-step)时,检查点会记录当前的图状态,包括配置、元数据、状态通道的值、下一个要执行的节点以及即将执行的任务等信息。这些检查点被保存到一个线程中,允许在图执行后访问。
通过检查点,Langgraph能够实现:
- 状态追踪:记录当前的执行状态,包括节点的输入、输出及依赖关系。
- 容错性:在执行中断时,可以从最近的检查点恢复。
- 调试和分析:通过回溯检查点,可以追踪图中每个节点的执行和数据流动情况。
超级步骤(Super-step) 是一种用于表示图执行过程中的一组并行操作的概念。用简单的语言来说,超级步骤是图执行的一个阶段,这个阶段中所有可以独立并行执行的节点都会被同时运行。
示例:
1 | from langgraph.graph import StateGraph, START, END |
使用 MemorySaver 类中的 list 方法列出检查点
1 | print("Listing all checkpoints:") |
列出检查点后,总计有4个检查点
- 空检查点,其中
START是接下来要执行的节点 - 具有用户输入
{'foo': '', 'bar': []}和node_a作为接下来要执行的节点的检查点 - 具有
node_a的输出{'foo': 'a', 'bar': ['a']}和node_b作为接下来要执行的节点的检查点 - 具有
node_b的输出{'foo': 'b', 'bar': ['a', 'b']}且没有要执行的下一个节点的检查点
获取特定检查点的状态(get_state)
参数:线程ID、检查点ID(未设置则获取该线程第一个检查点的状态)
1 | config = {"configurable": {"thread_id": "1", "checkpoint_id": "1efa5742-6335-62f2-8001-48489413a005"}} |
1 | StateSnapshot(values={'foo': 'a', 'bar': ['a']}, next=('node_b',), config={'configurable': {'thread_id': '1', 'checkpoint_id': '1efa5742-6335-62f2-8001-48489413a005'}}, metadata={'source': 'loop', 'writes': {'node_a': {'foo': 'a', 'bar': ['a']}}, 'thread_id': '1', 'step': 1, 'parents': {}}, created_at='2024-11-18T06:12:54.746187+00:00', parent_config={'configurable': {'thread_id': '1', 'checkpoint_ns': '', 'checkpoint_id': '1efa5742-6330-64cc-8000-2ec8c736999a'}}, tasks=(PregelTask(id='138cd50f-36f2-b67e-2bee-db094e8be206', name='node_b', path=('__pregel_pull', 'node_b'), error=None, interrupts=(), state=None, result={'foo': 'b', 'bar': ['b']}),)) |
Memory Store (记忆库)
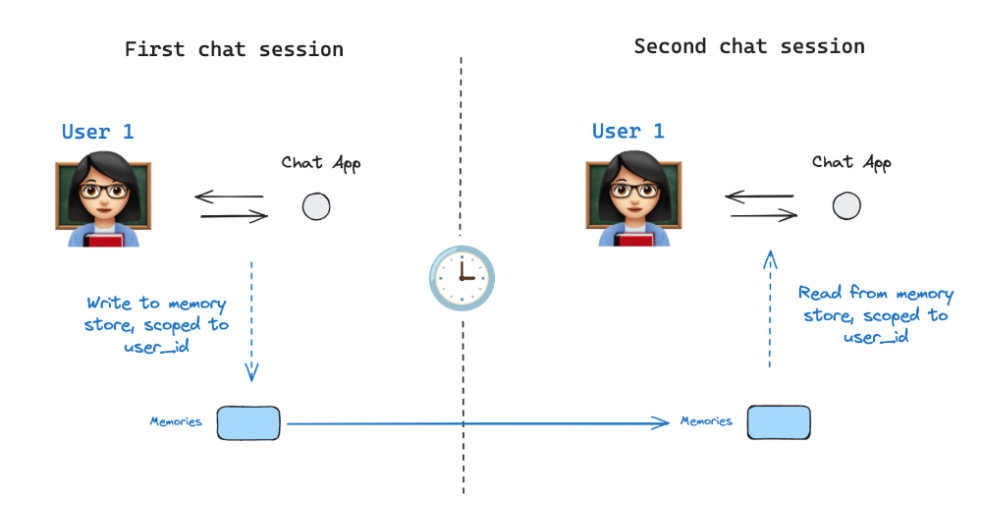
相当于将历史对话信息/有关用户的信息存储在一个类似数据库的”记忆库”中,通过定义一个InMemoryStore来跨线程存储有关用户的信息,然后再后续的线程中进行调用。
https://github.langchain.ac.cn/langgraph/how-tos/memory/manage-conversation-history/
Breakpoints
https://langchain-ai.github.io/langgraph/how-tos/human_in_the_loop/breakpoints/
可视化
官方提供三种可视化方法
- Mermaid.Ink
- Mermaid + Pyppeteer
- Graphviz
1 | # 编译图 |
代理模式
路由器
Router(路由器) 是一个强大的功能,用于动态控制图的执行路径。它允许根据 状态(State) 或某个函数的返回值,将执行流程引导到不同的节点。
功能:
- 动态路由: 根据
state或函数返回值,选择性地执行一个或多个后续节点。 - 条件分支: 根据某些条件,决定执行哪些分支节点。
1 | # 定义路由函数 |
- 支持并行处理: Router 可以同时将执行路径分发到多个节点。
1 | # 定义路由函数 |
工具调用代理
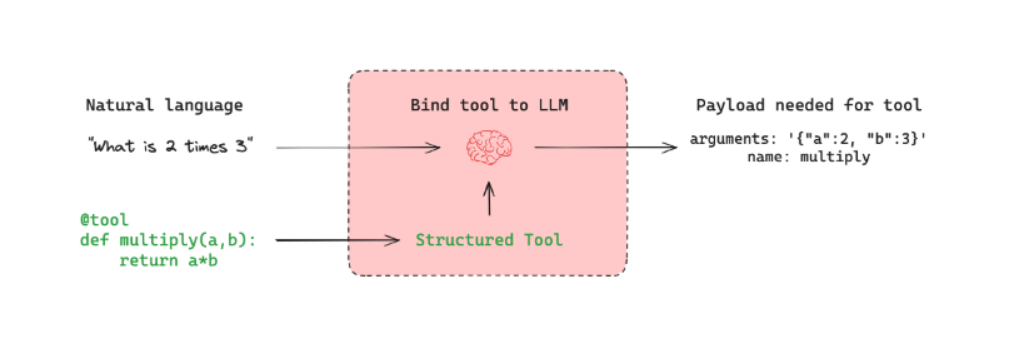
案例:
构建LangGraph步骤(LLM问答):
1.初始化模型和工具
1 | # 创建 LLM 实例 |
2.用状态初始化图
1 | # 定义状态类型 |
3.定义图节点
1 | # 定义节点函数 |
构建工作流图
1 | # 构建工作流图 |
4.定义入口点和图边
1 | # 增加节点 |
5.编译执行图
1 | # 编译图 |
6.可视化
1 | display(Image(chain.get_graph().draw_mermaid_png())) |
基本概念:https://langchain-ai.github.io/langgraph/concepts/low_level/#graphs
简单人机交互:https://readmedium.com/implementing-human-in-the-loop-with-LangGraph-ccfde023385c


